

Introduction to EIP-2535 Diamonds
Build large, modular smart contract systems that can be extended after deployment

Back in 2018 I was implementing an ERC721 token that could own/possess/control other ERC721 tokens and ERC20 tokens. To do this I was following ERC998 Composable Non-Fungible Token Standard, which is an extension of ERC721.
I had to implement ERC721 functions and ERC998 functions, plus some functions to implement custom functionality.
I found I couldn’t do this because I hit the 24KB maximum contract size limit. Solidity contracts are compiled to bytecode and the bytecode is deployed and stored on the Ethereum network. If the bytecode of a contract exceeds 24KB then it is rejected by the Ethereum network.
There are a number of things that can be done to reduce the bytecode of a smart contract such as making error messages smaller, tweaking compiler optimizer settings and using external functions of Solidity libraries.
Some of these options I didn’t want to do and some didn’t help enough. Also, none of these solutions solve the problem if I need too many external functions, because external functions add bytecode.
Perhaps I could have created a second contract to hold some of the external functions and state variables needed by the ERC721 token. But it doesn’t make sense to me for an ERC721 token to have some of its functions and state split into another contract and it would be more complicated and cumbersome to manage the state of ERC721 tokens when it exists in two or more contracts.
I wanted one storage space for all state variables and one Ethereum address from which I could design and implement all functions without bytecode size limitation. And I wanted all functions to read and write to state variables directly, easily and in the same way. It would also be nice to have optional, seemless upgrade functionality: to be able to replace functions, remove them and add new functionality without needing to redeploy everything. To be able to extend the smart contract system in a consistent, systematic way after it is deployed.
After a lot of work, feedback, help and experience, we have EIP-2535 Diamonds and reference implementations of it. It is a final Ethereum smart contract standard. A number of projects have implemented EIP-2535 in production and there are a number of security audits.
What is a Diamond
To the outside world (like user interfaces, other smart contracts, and software/scripts) a diamond appears to be a single smart contract with a single Ethereum address. But internally and hidden from the outside it utilizes a set of contracts called facets for its external functions.
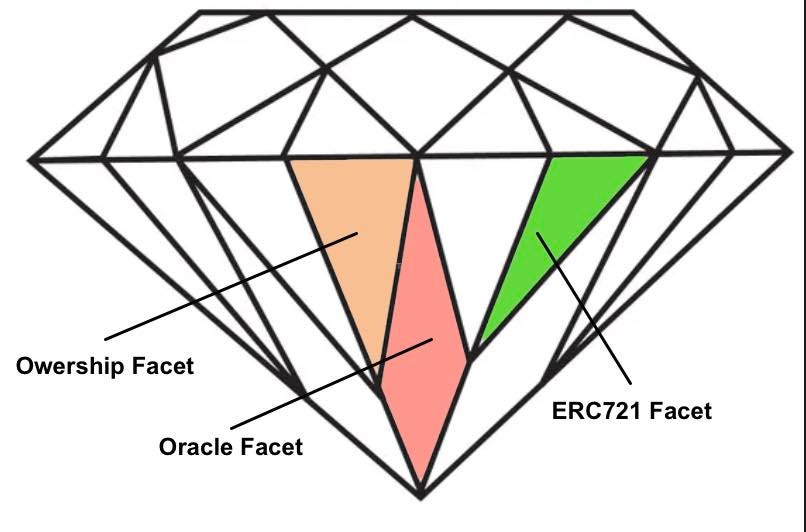
When an external software program such as another smart contract or user interface makes a function call on a diamond the diamond checks to see if it has a facet with that function and uses it if it exists.
Know these things to understand diamonds:
A diamond is a smart contract. Its Ethereum address is the single address that outside software uses to interact with it.
Internally a diamond uses a set of contracts called facets for its external functions.
All state variable storage data is stored in a diamond, not in its facets.
The external functions of facets can directly read and write data stored in a diamond. This makes facets easy to write and gas efficient.
A diamond is implemented as a fallback function that uses delegatecall to route external function calls to facets.
A diamond often doesn’t have any external functions of its own — it uses facets for external functions which read/write its data.
EIP-2535 specifies the mechanisms and contract interfaces for adding/replacing/removing functions and facets, and for inspecting diamonds to find out what functions and facets they have, and for recording upgrades. EIP-2535 enables software to be written that can work with or integrate with any and all diamonds.
Here’s a couple images to help visualize a diamond. The first image shows how functions are mapped to the facets that hold the function code:

This next image shows that all state variable data is stored in a diamond proxy contract and that code used by the diamond comes from facets. Keep in mind that it is possible for code within facets to defined structs with state variables, but all values stored are stored in a diamond proxy contract, not in facets. This image also shows that facets can have their own data within a diamond proxy contract, and can also share data with other facets. The image is just an example.
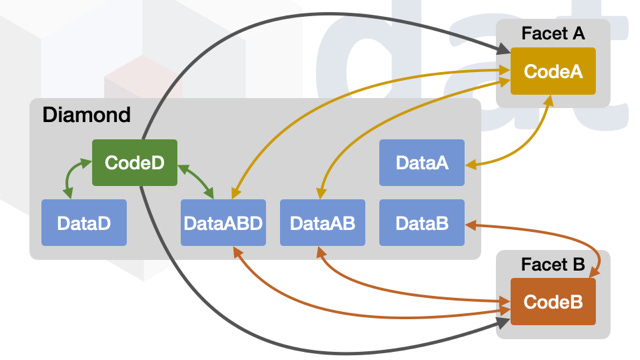
Organizing Facets of a Diamond
Facets can be organized like a file system. Here is how a file system is commonly organized:
Related and similar data are put in the same file.
Related and similar files are put in the same folder.
Related and similar folders are put in the same parent folder.
The facets of a diamond can be organized similarly:
Similar and related functions can be put in the same facet.
Similar and related facets can be put in the same folder.
Similar and related folders can be put in the same parent folder.
For example when implementing an ERC721 token the external functions from the ERC721 standard could be implemented in the same ‘ERC721Facet’ and custom functionality could be put in another facet.
Even if the 24KB max size contract limitation was removed I would still use EIP-2535 Diamonds because it provides a systematic way to organize, upgrade and extend a smart contract system.
Originally EIP-2535 Diamonds was created to solve the 24KB contract limit, but it turns out it is useful beyond that. It provides a framework for building larger smart contract systems and contract systems that can grow in production.
Keep Your Data Right
Solidity stores data in contracts using a numeric address space. The first state variable is stored at position 0, the next state variable is stored at position 1, the next state variable is stored at position 2, etc.
Facets of a diamond share the same storage address space because they have the same diamond and facets only read and write state variables in diamonds, not in themselves. If you don’t understand this then you need to understand how delegatecall works because all facet external functions are called with delegatecall from a diamond.
This is a problem if not handled correctly. For example let’s say that a diamond has two facets: FacetA and FacetB. Let’s say FacetA declares state variables ‘uint first;’ and ‘bytes32 second;’ and FacetB declares state variables ‘uint first;’ and ‘string name;’.
Both facets are storing `uint first` at position 0, so both facets can read and write that variable without problem.
But both facets are writing and reading something different at position 1 — ‘bytes32 second’ and ‘string name’. They are clobbering, or messing up each other’s data because they are interpreting and writing different data at position 1. This is why facets of the same diamond need to declare the same state variables in the same order if they are reading and writing to the same locations.
Strategies need to exist to make it easy for facets to declare the same state variables in the same order. This really isn’t a problem, even with upgrades, if you have a good strategy.
Inherited Storage
One simple strategy is to create a contract that declares all state variables used by all the facets of a diamond. It could be called ‘Storage’ or something. It could then be inherited by every facet. This strategy works and has been used successfully in production. But it has limitations and in my opinion I’ve found a similar but better strategy.
A limitation Inherited Storage has is that it prevents facets from being reusable. If you deploy a facet that uses Inherited Storage then you likely won’t be able to reuse that deployed facet with a different diamond that has different state variables.
Another limitation, in my opinion, is that it is too easy to accidentally name something like an internal function or local variable the same name as a state variable and have a name clash. Especially with a large diamond with 100 or more state variables. But perhaps this could be overcome by using code naming conventions that prevent such name clashes.
Diamond Storage
Different facets of the same diamond do not actually have to declare the same state variables in the same order if facets are storing data at different locations.
As mentioned earlier, Solidity automatically stores state variables at storage locations starting from 0 and incrementing by one. But we don’t have to use Solidity’s default storage layout mechanism. We don’t have to store data starting at location 0. We can specify where to start storing data in the address space. For different facets we can specify different locations to start storing data, therefore preventing different facets with different state variables from clashing storage locations. This is what Diamond Storage does.
We can hash a unique string to get a random storage position and store a struct there. The struct can contain all the state variables that we want. The unique string can act like a namespace for particular functionality.
For example we could implement an ERC721Facet. This facet could store a struct called ‘ERC721Storage’ at position ‘keccak256("com.myproject.erc721");’. The struct could contain all the state variables related to ERC721 that ERC721Facet reads and writes and nothing else. There are a couple nice advantages to this. One is that ERC721Facet is reusable. ERC721Facet can be deployed only once, and the deployed ERC721Facet can be used with multiple different diamonds that are using facets with different state variables. Another nice thing is that ERC721Facet is not cluttered with state variable declarations of variables it doesn’t use.
Another nice advantage to Diamond Storage is that it is possible for the internal functions of Solidity libraries to access Diamond Storage just like any facet function. Solidity libraries are a great way to share internal functions between different facets. I wrote a blog post about using Solidity libraries with Diamond Storage here: Solidity Libraries Can't Have State Variables -- Oh Yes They Can!
Diamond Storage is particularly useful for creating reusable facets. These facets are deployed once and can be reused by lots of different diamonds. The current reference implementations of diamonds use Diamond Storage for the DiamondCutFacet, DiamondLoupeFacet and OwnershipFacet facets. These can be deployed once and used by lots of different diamonds.
Checkout the example of Diamond Storage in EIP-2535 Diamonds.
For more information about Diamond Storage and another code example, see this blog post: How Diamond Storage Works. I also recommend reading Understanding Diamonds on Ethereum.
AppStorage
AppStorage is similar to Inherited Storage but it solves the name clash problem where it is too easy to accidentally name something like an internal function or local variable the same name as a state variable. This might seem a trivial matter but I found in practice it is very nice because AppStorage also distinguishes code in a way that makes it easier to scan and read. If you care about code readability then you will like AppStorage.
AppStorage enforces a naming or access convention that makes it impossible to clash names of state variables with something else.
A struct called AppStorage is written in a Solidity file. The AppStorage struct contains state variables that will be shared between facets. To use it a facet imports the AppStorage struct and declares `AppStorage internal s;` as the first and only state variable in the facet. The facet then accesses all state variables in functions via the struct like this: `s.myFirstVariable`, `s.mySecondVariable`, etc. Here is an example:
// AppStorage.sol
struct AppStorage {
uint256 secondVar;
uint256 firstVar;
uint256 lastVar;
...
}// StakingFacet.sol
import "./AppStorage.sol"
contract StakingFacet {
AppStorage internal s;
function myFacetFunction() external {
s.lastVar = s.firstVar + s.secondVar;
}
}It is important that ‘AppStorage internal s;’ is declared as the first and only state variable in all facets that use it. That puts it at position 0 in the storage address space. So if all facets declare it as the first and only state variable then the storage data between facets will line up correctly. Don’t add more state variables directly to a facet because that will clash with the state variables declared in the AppStorage struct. To add more state variables add them to the end of the AppStorage struct or use Diamond Storage.
AppStorage is more convenient to use than Diamond Storage because in every function Diamond Storage requires getting a pointer to a struct, whereas with AppStorage the `s` struct pointer is automatically available throughout a facet.
Another advantage that AppStorage has over Inherited Storage is that AppStorage can be accessed by Solidity libraries in the same way that Diamond Storage can. An AppStorage struct is always stored at location 0 so internal functions in Solidity libraries can use this to initialize the ‘s’ storage pointer to point to the AppStorage struct. Here is an example of that:
//LibAppStorage.sol
struct AppStorage {
uint256 secondVar;
uint256 firstVar;
uint256 lastVar;
...
}
library LibAppStorage {
function diamondStorage()
internal
pure
returns (AppStorage storage ds) {
assembly {
ds.slot := 0
}
}
function myLibraryFunction() internal {
AppStorage storage s = LibAppStorage.diamondStorage();
s.lastVar = s.firstVar + s.secondVar;
}
function myLibraryFunction2(AppStorage storage s) internal {
s.lastVar = s.firstVar + s.secondVar;
}
}A storage pointer to an AppStorage struct can also be passed into library functions as an argument, as can be seen in the `myLibraryFunction2` function above.
AppStorage can be used with contract inheritance. This is done by declaring ‘AppStorage internal s;’ in a contract. Then all facets that use AppStorage inherit that contract.
AppStorage is particularly useful for application or project specific facets that won’t be reused across different diamonds that use different storage. AppStorage can be used with Diamond Storage in the same facet, and this is common to do.
AppStorage is also useful in normal smart contracts because it makes code more readable and prevents name clashes.
Checkout this blog post about AppStorage for more information: AppStorage Pattern for State Variables in Solidity
Diamond Deployment
A diamond is deployed by adding at least a facet to add the ‘diamondCut’ or other upgrade function in the constructor of the diamond. Once deployed more facets can be added using the upgrade function.
A ‘Single Cut Diamond’ can be created by adding all facets a diamond will ever have in the constructor of the diamond and leaving out any kind of upgrade function. This kind of diamond is not upgradeable.
Here is a link to a script that deploys a diamond: https://github.com/mudgen/diamond-3-hardhat/blob/main/scripts/deploy.js
Diamond Upgrades
EIP-2535 Diamonds specifies the ‘diamondCut’ function which is used to add/replace/remove any number of facets and functions to a diamond in a single transaction. It can be important to execute an upgrade in a single transaction so that a diamond does not get into an inconsistent state at any time.
The ‘diamondCut’ function can also optionally execute an arbitrary external function with delegatecall during an upgrade. This is to initialize state variables and otherwise make any changes needed for an upgrade.
Here is a link to a test script that shows various examples of upgrading a diamond: https://github.com/mudgen/diamond-3-hardhat/blob/main/test/diamondTest.js
Keep State Variables Safe
It is important not to corrupt state variables during an upgrade. It is easy to handle state variables correctly in upgrades.
Here’s some things that can be done:
To add new state variables to an AppStorage struct or a Diamond Storage struct, add them to the end of the struct. This makes sense because it is not possible for existing facets to overwrite state variables at new storage locations.
New state variables can be added to the ends of structs that are used in mappings.
The names of state variables can be changed, but that might be confusing if different facets are using different names for the same storage locations.
Do not do the following:
If you are using AppStorage then do not declare and use state variables outside the AppStorage struct. Except Diamond Storage can be used.
Do not add new state variables to the beginning or middle of structs. Doing this makes the new state variable overwrite existing state variable data and all state variables after the new state variable reference the wrong storage location.
Do not put structs directly in structs unless you don’t plan on ever adding more state variables to the inner structs. You won't be able to add new state variables to inner structs in upgrades. This makes sense because a struct uses a fixed number of storage locations. Adding a new state variable to an inner struct would cause the next state variable after the inner struct to be overwritten. Structs that are in mappings can be extended in upgrades, because those structs are stored in random locations based on keccak256 hashing.
Do not add new state variables to structs that are used in arrays.
When using Diamond Storage do not use the same namespace string for different structs. This is obvious. Two different structs at the same location will overwrite each other.
Do not allow any facet to be able to call `selfdestruct`. This is easy. Simply don’t allow the `selfdestruct` command to exist in any facet source code and don’t allow that command to be called via a delegatecall. Because `selfdestruct` could delete a facet that is used by a diamond, or `selfdestruct` could be used to delete a diamond proxy contract.
These rules will make sense if you understand how Solidity assigns storage locations to state variables. I highly recommend reading and understanding this section of the Solidity documentation: Layout of State Variables in Storage
Here is a link to an article that shows an example of doing an upgrade on a diamond that adds new state variables:
More detailed information about how diamond upgrades work can be found in this article: How Diamond Upgrades Work
Inspecting Diamonds with Loupe Functions
A loupe is a special magnifying glass for looking at and inspecting diamonds.
EIP-2535 Diamonds specifies four standard functions for showing what facets and functions a diamond has. These are called the loupe functions. More information about loupe functions is here: Diamond Loupe Functions
louper.dev is a website that is used to display information about diamonds and execute their functions.
What’s with the Diamond Terminology?
It is a conceptual model. A real physical diamond has different sides, different facets. An Ethereum diamond also has different sides, facets, as sets of related functions. After gaining experience implementing diamonds your mind will divide into different functions sets that are tied to a common core — the Ethereum address and the state of a diamond. Similar in a way to how the facets of a physical diamond are connected to a common center.
Sometimes an upgrade is called a cut. People unfamiliar with physical diamonds might wonder how diamonds, being a very hard substance, can be cut. But that’s how retail diamonds are made. They are physically cut to make or add facets.
A loupe is a special magnifying glass for looking at and inspecting diamonds.
Get Started Making Your Own Diamond
Use an existing diamond implementation to get started making your own diamonds.
Here is a blog post with a list of smart contract security audits of diamond implementations: Smart Contract Security Audits for EIP-2535 Diamonds Implementations
Learn More
Subscribe to this blog:
Join the EIP-2535 Diamonds discord: https://discord.gg/kQewPw2
Follow and talk to me on twitter: https://twitter.com/mudgen